
0x00 前言
最近想学一下爬虫的进阶用法,比如模拟登录之类的,在网上找的教程里面所用的测试网站现在已经加了反爬虫机制,目前我还太菜,还过不了反爬机制。但是忽然想到了学校还有个垃圾强智系统,漏洞百出,应该也不会加反爬机制,所以拿强智练练手。
0x01 用浏览器初探
信息搜集
这里只需用Chrome浏览器的开发者工具(F12),也不需要用BP之类的抓包工具
打开网站,强智-山东科技大学,打开开发者工具–Network–勾上Preserve log,然后用自己的账号登录。

然后可以看到有挺多信息的,
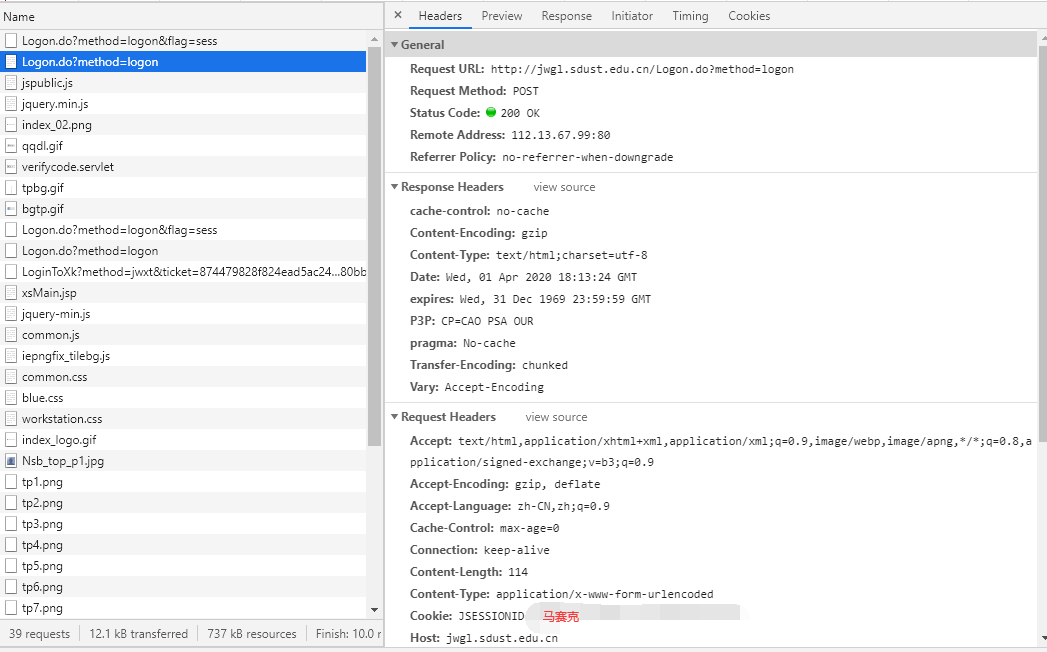
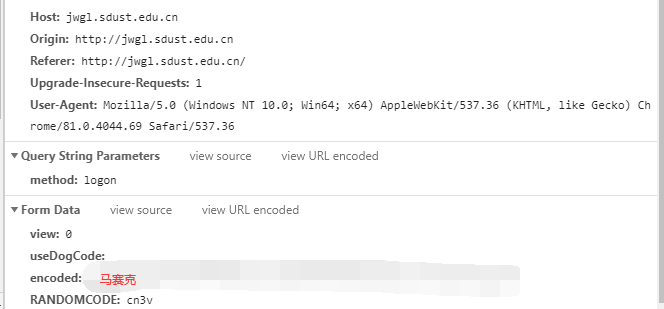
这里有几个关键的信息:
1 | Request URL: http://jwgl.sdust.edu.cn/Logon.do?method=logon |
这些信息向我们指明了真实请求的URL、请求方法、Origin、Referer、User-Agent、Post所传参数。
陷入困境
这里post所传参数与我想象的有所不同,我以为会传入用户名、密码、验证码,但是实际上只有一个encoded和验证码。
盲猜可能通过某种加密方法将用户名和密码加密成了encoded,因为我从这个encoded里面看到了我密码的一部分,而且密码像插队一样插在encoded中。
多次重新登录并查看这个encoded发现这个值是会变的,也就是说加密算法应该是有一个动态的参照,或者是随机数种子(结合一些web知识,随机数种子不太现实)?
那么该如何通过用户名和密码来得到这个encoded?
柳暗花明
困扰了一会以后,我看了一下网页源码,我看到了一段令我惊喜的代码。

这里写了encoded的生成算法,果然是由用户名和密码以及dataStr计算得来。
dataStr是通过/Logon.do?method=logon&flag=sess生成的
刷新几次可以看到每次生成的结果都不同。
把JS代码转化成Python代码即可得到encoded。
0x02 用爬虫初探
获取验证码
从网页源码里面可以看到,验证码是在这个网站获取的
那么我们同样可以去这个网站获取验证码,由于我现在还没法很完美的实现验证码的自动识别,这里采用将二维码show出来手工输入的办法。
Session
由于验证码生成网站和dataStr生成网站每次刷新,里面内容都会不同
那么我们该如何实现爬虫传的参数 与 我们生成的dataStr和验证码的统一?
这里通过创建session对象来实现统一。
如何测试是否登录成功
可以打印一下post以后的内容,看看是不是和用浏览器登录进去的一样,不能通过看post的state_code。
代码(demo)
1 | # -*- coding: UTF-8 -*- |
放一张表明登录成功的截图吧。

代码2(demo)
4月3号更新了一些小功能,做了一些优化,但程序依然还只是个雏形。
1 | # -*- coding: UTF-8 -*- |
代码3(demo)
一次偶然的机会在网上找到了一个关于过强智网站验证码识别的代码。
比较特殊,强智的验证码里面只有123zxcvbnm这些字符,因此过验证码的难度大大降低。
1 | #orc.py |
1 | #char_lists.py |
1 | # -*- coding: UTF-8 -*- |
测试发现,这个代码对m和n的识别度较差,其他都很好,总体识别成功率还是有80%左右的。
0x03 Maybe have more
完成登录以后就可以嘿嘿嘿了。

最后吐槽一句:垃圾强智系统爬爬爬

