
0x00 前言
被老师安排带着20级的学弟去了聊城市的”第三届山东新一代信息技术创新应用大赛–信息安全攻防赛项”
做题时,我各个题目时间分配不太合理…或许我应该先帮忙把杂项做完,而不是一直在纠结这个逆向题以及pwn的libc问题…痛失一等奖
pwn没给libc,用libcsearcher也不管用,导致远程一直没打通,但是事后询问了一位师傅,他直接大胆猜测libc就是2.23的…也确实打通了…看来我还是缺少经验555
逆向一共3个,前俩没啥亮点,但是第三个挺难搞,虽然分值还没re2高
赛后趁没课赶紧复现了一下。
题目附件: 下载地址
0x01 分析
程序Base64_changed.exe未加任何壳,直接拖入IDA分析。
来到main函数,其中有一部分符号我已经重命名了。
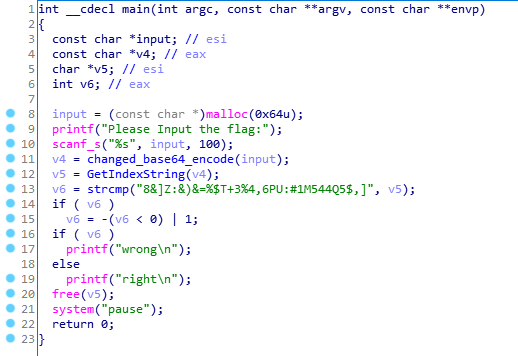
从main函数来看,程序逻辑非常简单,先进行输入,然后对输入进行一次changed_base64_encode然后再对其结果进行一次GetIndexString操作。
具体分析一下:
changed_base64_encode
起初我并没有对这个函数进行细看,只以为这个函数只是单纯的进行了换了表的base64_encode。
但赛后复现的时候却发现了很关键的一处!
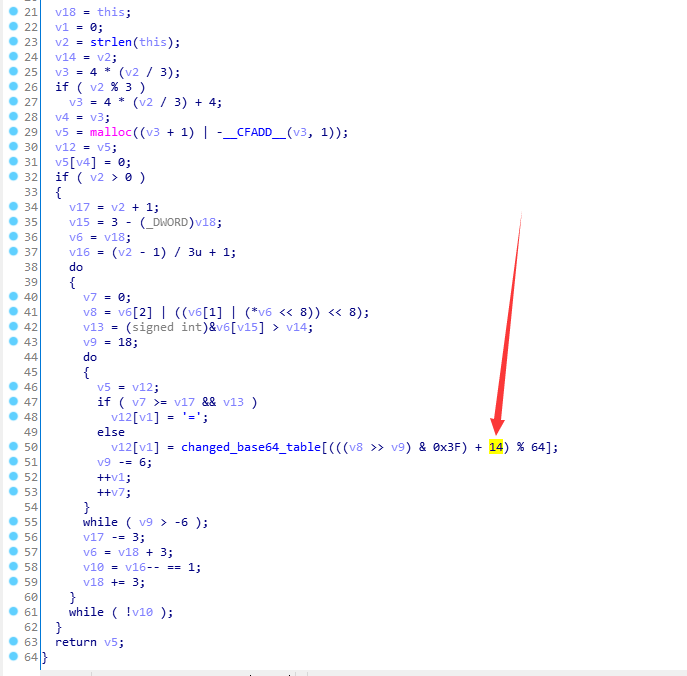
这里有个+14,即对索引加了14
那么为了使我们现有的base64_decode算法能正常运行(或者去直接修改base64_decode算法,但这样比较麻烦)
需要手动将changed_base64_table进行了一次整体左移14位!
1 | .rdata:00403160 ; char changed_base64_table[] |
本身这个base64_table就已经是被改过的,这下还要进行移位,也就相当于这次base64_encode真正用的表为OPQRSTUVWXYZ0123456789+/abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMN
GetIndexString
要看懂这个函数在干什么的话,一定!一定!一定!要先理解base64算法,网上有很多详解,这里不再叙述。
这个函数主要就是模拟base64加密时获取索引的操作,
然后执行 索引的值+32 --> ascii --> 字符(虽然字符在内存中也是以二进制形式存在,但是这样描述大概能方便理解) , 并把字符依次拼接形成字符串,最后返回这个字符串。
提取出来主要算法如下:
1 | v6 = 0 |
不过还是有两点非常细节的地方!
首先,获取到索引的时候,进行了 +32 的操作
其次,v5[v6+1]也就是每组(每四个一组)索引中的第二个索引与每组中的其他三个索引不同。
其他三个索引,是按照base64_encode算法求出以后再进行+32操作
但第二个索引
v5[v6 + 1] = ((second >> 4) + 32) | 16 * (first & 3);
是取了每组(每三个一组)待加密字符串中第二个字符的前四位加上32以后与16 * (first & 3)进行或运算。
而并非按照base64_encode原本的算法先求出(second >> 4) | 16 * (first & 3) ,然后再按照程序的意愿进行+32
隐含的问题
这样就会导致一个问题:
说白了就是由于这个程序进行的是((second >> 4) + 32) | 16 * (first & 3)操作,导致每组索引中的第二个索引从左向右第三位(算上为了补齐8位而在开头补的2个0)总会是1。
因此在逆这个算法的时候需要对其分情况讨论,讨论还原真正的IndexString的时候是否需要减去32
下面举两种情况来说明:
情况一
假设我们待加密的字符串为Gwn
其二进制表示为01000111 01110111 01101110
用first表示第一个字符,用second表示第二个字符。
((second >> 4) + 32) == 100111
16 * (first & 3) == 110000
((second >> 4) + 32) | 16 * (first & 3) == 110111
而
((second >> 4)) == 000111
16 * (first & 3) == 110000
((second >> 4)) | 16 * (first & 3) == 110111
通过上述可以发现,如果每组待加密字符串的第一个字符的从左往右第7位为1,也就是获取的每组索引中的第二个索引的从左往右第3位(因为前2位要补0形成8位byte类型)为1
那么就有((second >> 4) + 32) | 16 * (first & 3)就等于((second >> 4)) | 16 * (first & 3)
情况二
但如果我们待加密的字符串为Ewn呢?
其二进制表示为01000101 01110111 01101110
用first表示第一个字符,用second表示第二个字符。
((second >> 4) + 32) == 100111
16 * (first & 3) == 010000
((second >> 4) + 32) | 16 * (first & 3) == 110111
而
((second >> 4)) == 000111
16 * (first & 3) == 010000
((second >> 4)) | 16 * (first & 3) == 010111 == (((second >> 4) + 32) | 16 * (first & 3))-32
也就是说如果每组待加密字符串的第一个字符的从左往右第7位为0,也就是获取的每组索引中的第二个索引的从左往右第3位(因为前2位要补0形成8位byte类型)为0
那么就有((second >> 4) + 32) | 16 * (first & 3)就等于(((second >> 4)) | 16 * (first & 3)) + 32
0x02 思路
由程序用于对比的字符串8&]Z:&)&=%$T+3%4,6PU:#1M544Q5$,]
想办法还原出真正的IndexString,这里可以考虑爆破,毕竟真正需要爆破的是每组(每四个一组)中的第二个索引中的从左向右第3位(按总共8位来算),这个字符串长度32,需要爆破8个位置,每个位置2种情况,最多需要爆破2的8次方即256次。爆破成功与否需要看能否正常解密得到flag。
还原出真正的IndexString以后,也就得到了正确的索引,也就可以根据索引按照真正的base64加密算法得到一个base64串,然后进行base64decode,就得到了我们input进行程序的changed_base64_encode后的结果。
然后对这个结果进行base64换表decode即可得到flag。
0x03 解密脚本
比较菜,目前只想出了用随机数进行爆破和直接套8次for循环的爆破,8次for循环太麻烦了,这里用的随机数。
应该还有更好的爆破方法吧
1 | # -*- coding: UTF-8 -*- |
爆破的话能爆破出来好几种解,比如:
1 | flag{BAsE>4aBB64} |
经过测试,这些都能通过程序的验证。
0x04 写在最后
主办方在群里发过一段解密脚本,但是程序strcmp的那个字符串与这个程序有些许差别。
大概这个程序是经过改编的,而且我感觉上面分析的那个+32的问题,应该是改编时没注意括号导致的?
不过这道题目还是挺有意思的,考察对base64算法的具体理解,单单会用Python或者其他语言里面现有的encode与decode还是不够的。
如果有人看到了这篇博客并且想到了更好的爆破方法,希望能够教教弟弟。


