
0x00 前言
太久没有更博客了,今天记录一下前段时间学到的完整性检测绕过,比如绕过CRC检测。
像一些程序,总会有一些完整性检测比如CRC。当用逆向工程的方法修改程序的代码时,程序可能会做出响应的对抗操作。
0x01 分析
这类检测往往是对程序的代码段进行CRC检测来判断程序的代码段是否被修改,进行CRC检测有许多好处,如能防止通过修改程序代码来暴力破解一些软件等
CRC校验值往往会存在内存中的某个位置
CRC检测的代码也会位于代码段
CRC检测几乎都会有cmp 正常情况的CRC,实际检测到的CRC然后跳转的操作。
基于如上分析,不难有以下几种思路,可能有不对的地方,还望各位大佬斧正!
思路一
在不改变代码段的情况下,找到存放CRC校验值的内存地址,跟踪这个内存地址,找到CRC检测的相关汇编。
然后去修改cmp 正常情况的CRC,实际检测到的CRC后的跳转,强行让程序往”检测无误的方向”进行跳转。
本思路优点:简单粗暴,省时省力。
本思路缺点:可能会有暗门。
思路二
在不改变代码段的情况下,找到存放CRC校验值的内存地址,跟踪这个内存地址,找到CRC检测的相关汇编。
然后主动按照我们的意愿来修改代码段,然后主动用CRC算法来得到修改后的代码段的校验值,然后将这个校验值存到一个不用的内存地址中。
强行修改CRC检测相关汇编的传地址过程以实现cmp 我们存的CRC校验值,实际检测到的CRC校验值的效果,按照前面的操作,我们存的CRC校验值就应该与实际检测到的CRC校验值相等,从而使得程序往”检测无误的方向”跳转。
本思路优点:呃……
本思路缺点:①实现过程中(主动修改代码段但还没来得及修改cmp部分时),有可能直接触发CRC检测未通过;②实现起来较为麻烦;③用来存放我们计算得到的CRC校验值的时候,这个存放地址有可能选到奇奇怪怪的会触发异常的位置(虽然可以凭经验来选到一些好位置)
思路三
不改变代码段,将整个代码段复制到一个不用的内存地址,同思路一和二找到CRC检测的相关汇编
这次是去修改CRC检测相关汇编的扫描起点与扫描终点,也有可能是扫描起点与扫描长度的形式
让程序去扫描我们存的代码段备份,这样我们就能放心对程序的代码段进行修改了
本思路优点:①这种”乾坤大挪移”的思想很爽;②用这种思路写出来的脚本的通用性较强,大部分情况下只需要修改脚本的部分内容就能实现绕过检测。
本思路缺点:①实现起来略有些麻烦;②空间复杂度较高。
思路四
这个思路源自《加密与解密》第四版P546的⑧
思路类似于思路三,只不过这次是依然检测原始部分,但执行新部分。
1 | 重新将要HOOK的模块加载到内存中,然后人为制造异常,把执行流程切换到新加载的模块中。在新加载的模块中仍然可以进行各种HOOK操作,此时守方的检测程序仍然在检测原始的模块,这样就检测不到HOOK了。 |
0x02 Do it!
以CE自带的CE Game tutorials为例,采用思路三

当修改它的代码段时,标题会变成(Integrity check error)
将代码段还原以后,标题就恢复正常
定位与分析
首先我们要找一段汇编代码段,要找出是什么访问了该汇编代码段。
下面先来寻找一段代码段:这里就找一段和靶子血量相关的汇编代码吧,借助CE可以很简单地找到靶子血量的内存地址,找出什么访问了这个地址(靶子血量地址),从而发现这么一段给靶子血量赋值的汇编代码,并记录下来这段汇编代码的地址10003F45D。

接下来,我们要找到是什么一直持续访问这段汇编代码(mov eax,[rcx+70])
由于我使用的无插件的CE,无法直接在Memory Viewer中右键汇编代码然后查找什么访问了这段汇编代码
无奈只能手动在CE中添加这段汇编的地址
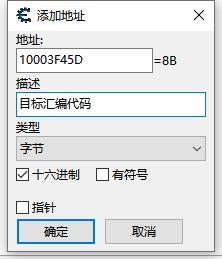
确定后,进而右键-找出是什么访问了这个地址
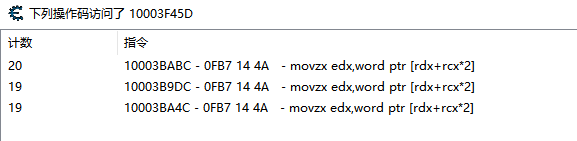
可以发现这里有三个位置持续访问该代码段。
选择10003BABC处查看其反汇编
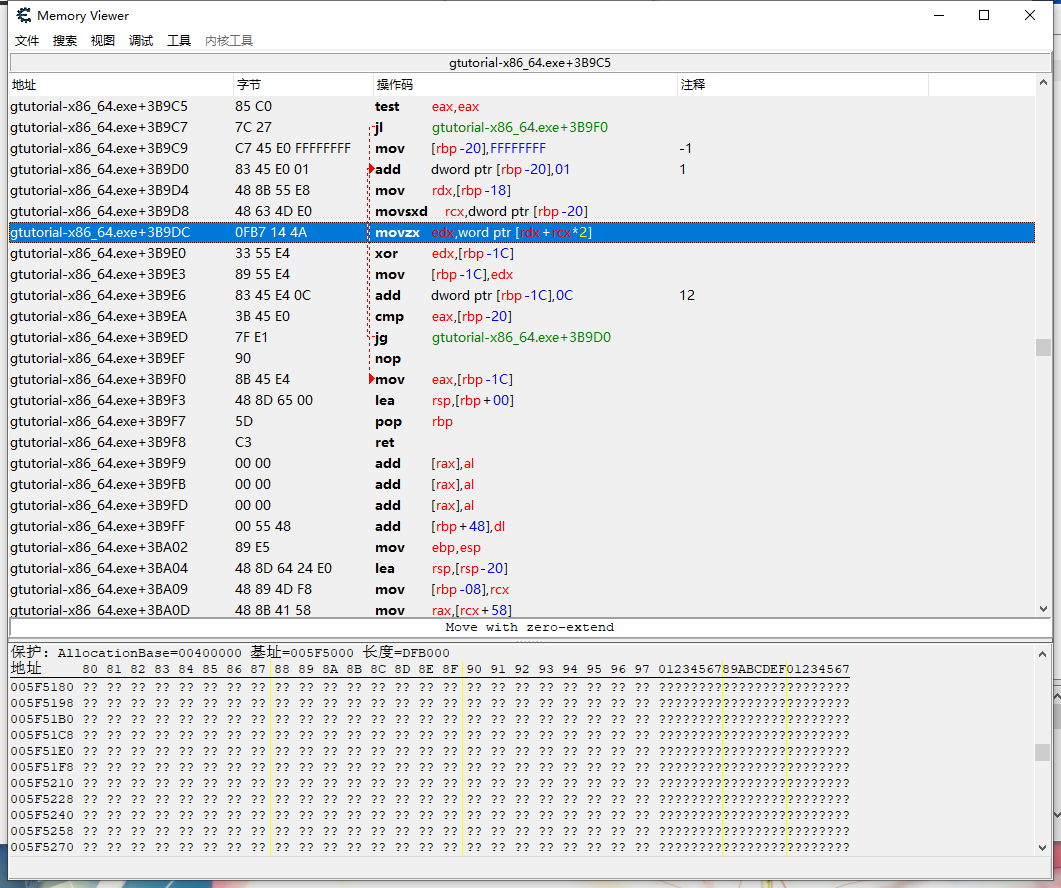
不难发现rdx+rcx*2处的值应该就是待比较的值。
下面需要理清一个关系,在代码段中,每条语句对于该代码段的基址的偏移是固定的,正如这句movzx edx,word ptr[rdx+rcx*2]相对于代码段的基址的偏移为0x389DC。
那么同样的,如果我们将代码段复制一份到其他内存中,我们可以知道复制过去的代码段的基址,加上这个偏移,同样是可以得到这个语句!对任意代码段的语句均是如此!
即复制过去的语句的地址 = 复制过去的代码段基址 + 偏移量
因此,需要移花接木,让负责CRC扫描的代码去扫描我们新复制过去的代码段。故可得如下伪代码:
1 | 复制代码段到内存的其他位置并记录复制过去的代码段的基址addressOfCopy |
修改
由于这三个位置也位于代码段,所以我们必须保证这三个位置同时被修改。
下面尝试CE自带的自动汇编
对这三个位置中任意一个右键-在反汇编程序中显示地址-工具-自动汇编-模板-CT表框架代码;模板-代码注入-确定即可
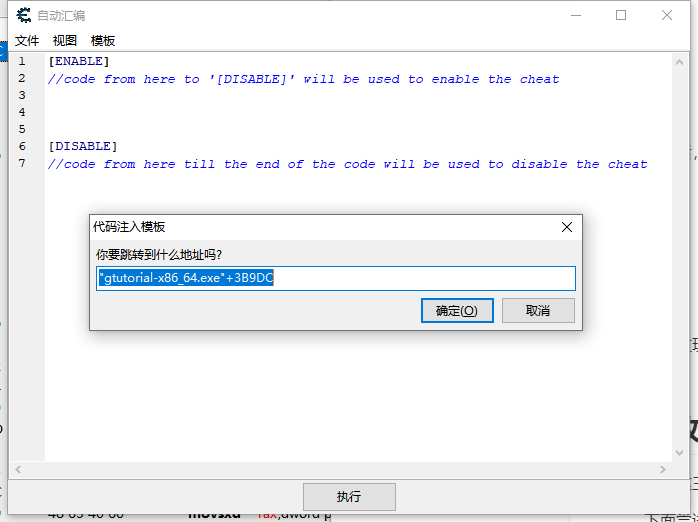
保持这个自动汇编窗口不关闭
然后依次对另外两个位置 右键-在反汇编程序中显示地址(目的主要是定位到这个位置,后续点击代码注入后框框里面直接就是这个地址了,算是借助CE的一些方便之处来省时省力了),然后模板-代码注入-确定。
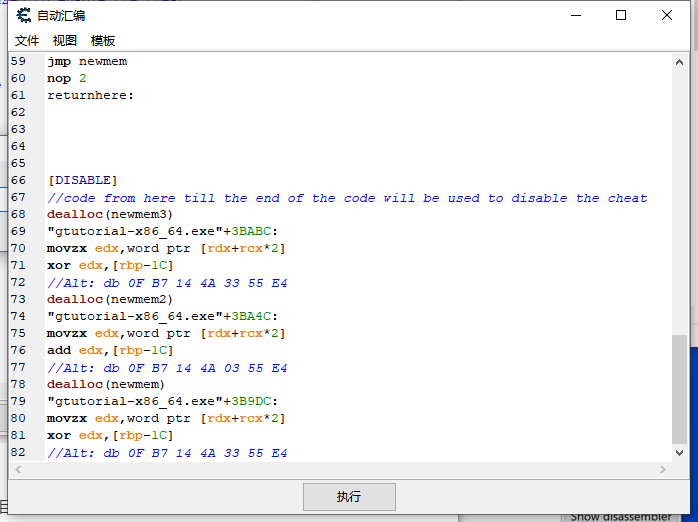
这么弄完以后就已经生成了82行的框架了,不得不说CE在自动汇编这块确实比方便。
采用思路三,我们需要先将代码段进行一次备份。
1 | {$lua} |
1 | {$asm} |
db定义字节类型变量,占1字节
dw定义字类型变量,占2字节
dd定义双字类型变量,占4字节
dq定义四字类型,占8字节
接下来就是HOOK了
这里以第一个位置10003B9DC为例,写满了注释,应该比较好理解,可以结合着程序执行流程图来更好的理解。
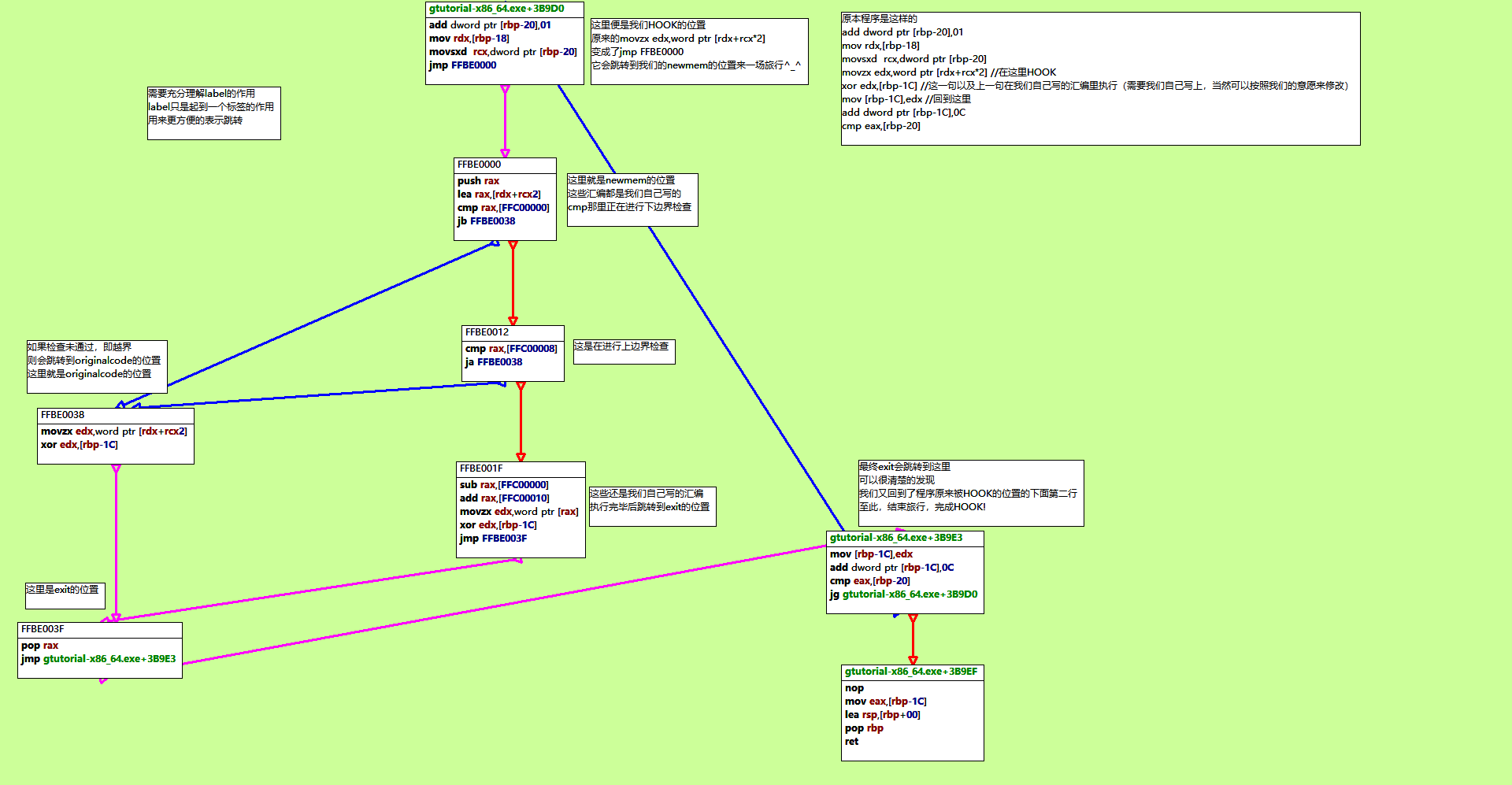
1 | //below 4 lines are automatically generated by CE |
关于label,它只是一个标签,可以更方便的标识一段代码,是为了能更方便的实现跳转等。
接下来只需要复制粘贴,稍作修改,就能适配其他两个位置了。
需要修改的地方有
1 | 所有label的位置 |
0x03 完整脚本
CE脚本
因为是CT脚本,应该是可以保证这些操作的原子性?
不过可以确定的是,这些操作应该是可以在极短时间内(小于一个CRC检测周期与CRC检测间隔)完成,经过多次实验,并不会在脚本执行时导致检测未通过。
另外,顺序是按照第三部分、第二部分、第一部分来的,这也是由于CE模板先添加了第一部分,其次才添加了第二第三部分的缘故,有FILO的味道了。
1 | [ENABLE] |
0x04 写在最后
应该有一年多没有更博客了
一年内主要在备战考研,当然也在摸鱼
也算是运气不好吧,未能一战成硕
二战也未必是一件坏事,能让自己改掉一些毛病比如拖延症
在写这篇博客的时候,我确实感受到了学习知识然后分享知识的这种Input then output的快乐
我也有太多的东西想去学习
以后的日子里,我也会勤更一下博客,少摸鱼
二战,好好努力,愿不负自己的努力!


